Face filters on the web from just text descriptions
The last few months of GAN progress has been amazing to watch. The ability to generate images from just text descriptions has been suddenly unlocked thanks to OpenAI's CLIP and with it a flood of exciting possibilities.
In this post I'll describe a project I did to create face filters for cats - all running locally in javascript - that only uses text descriptions (e.g. "a cat with heart shaped eyes") to guide the transformation (no data gathering needed).
Background
Perhaps the most famous technique that CLIP has spawned in the last few months is the very interesting VQGAN+CLIP combination (originally written by Ryan Murdock). Suddenly generating artworks from only a text description seems to have been unlocked (with new improvements coming every week - the CLIP guided diffusion colab written by Katherine Crowson being one of more striking recent advancements). As impressive as these tools are though, the fact that you're nearly stuck on colab to try them out has kind of limited how much fun you can have and how widely they're able to spread outside of GAN fan communities.
The thing that would really make them accesible to other parts of the internet (e.g. people focusing on frontend or even normal non-coders who don't have time resources to get into colab twiddling) is if these advances could be distilled and compressed enough to run on standard hardware (or even mobile web) and abstracted enough to be as easy to play with as importing an npm package. Many people probably consider resource expensive computation and state of the art GAN toys to be impossible to untangle, but with a bit of work and by smartly constraining the flexibility of the models, I don't think it is.

There's probably hundreds of low hanging fruits here still but one idea that struck me as easily pluckable is recreating on the web some sort of snapchat-like face filter. (The idea of doing this was heavily inspired by Doron Adler and Justin Pinkney's interesting "toonify" app that they insightfully wrote about here and is testable here.) There's been many GAN based filters like this in the past 5 or so years, with gender reversal being one of the first and the "pixar filter" one of the latest and more impressive examples. In the past most of these have required probably thousands upon thousands of real life image pairs. It's not until the last 6 months or so that CLIP has unlocked the ability to manufacture a filter like this from only a text prompt.
How? Mostly thanks to the heavy lifting of StyleGAN-nada. While VQGAN+CLIP creates funky and cool art pieces, where CLIP really seems to shine in terms of creating high quality results is when it's acting on a sort of really well trained subspace, e.g. StyleGAN. One of the first things that illustrated this in a very impressive way was StyleCLIP. With this I-can't-believe-it's-not-magic tool a user can take a face and augment the image in a desired way only using a text description. A frowning face plus "a smiling person" produces someone happy. An image of a cat plus "cute" gives you an adorable kitten.

This seems ideal for the project in mind above. To achieve the goal of state of the art GAN tech running locally without backend processing, we would just have to produce a lightweight enough model and then stuff it full of thousands of pairs of cat faces. You would grab a cat face image, transform it to make it "a cat with heart shaped eyes" and then feed input and output pairs like that over and over into the lightweight model until it figures out how to transform arbitrary cat faces cheaply in your phone. The wrench in this idea is that StyleCLIP takes a bit too many seconds to massage the input into its desired output shape, and at a minimum of at least 20k or so image pairs that means days of waiting for a full dataset.
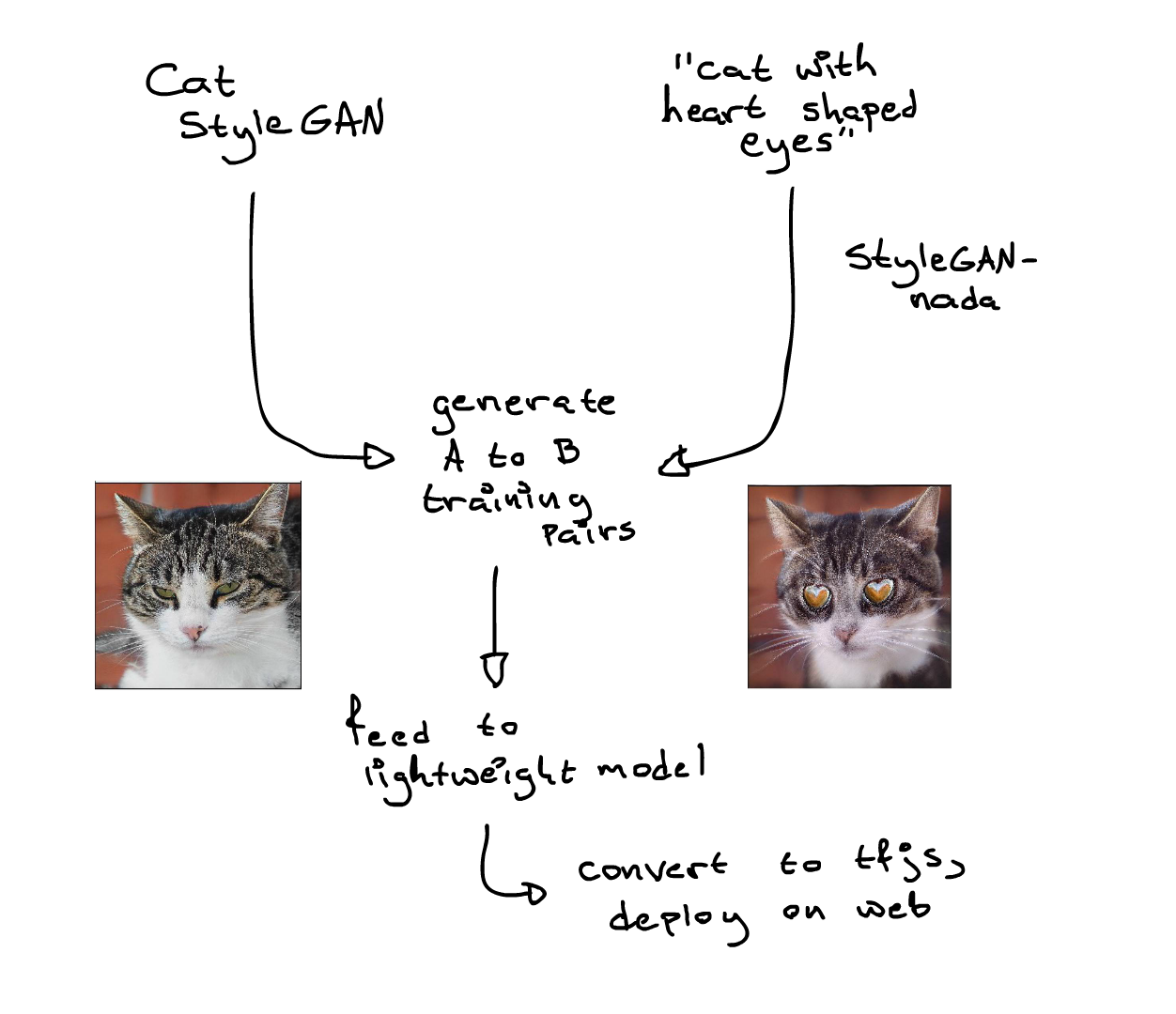
Fortunately this is where the only three month old StyleGAN-nada comes in handy. Instead of transforming individual images (like StyleCLIP) what StyleGAN-nada does is take a StyleGAN checkpoint and a text prompt, simmer for only about 10-30 minutes, and then it produces an entirely new StyleGAN model whose walk around the latent space are images that fit the description. Once this has been trained and you have the two networks in hand, generating arbitrary thousands of training pairs takes no time at all. (Sampling from two StyleGAN networks is much faster than performing a StyleCLIP transformation on one image.)
Results
So that is what this project does. First it generates 50k image pairs using a cat StyleGAN and a StyleGAN-nada transformation. Then it feeds those to a lightweight pix2pix model which is attached to a preprocessor that finds and aligns cat faces (using this model) and then stitches the output back into the input with poisson blending.
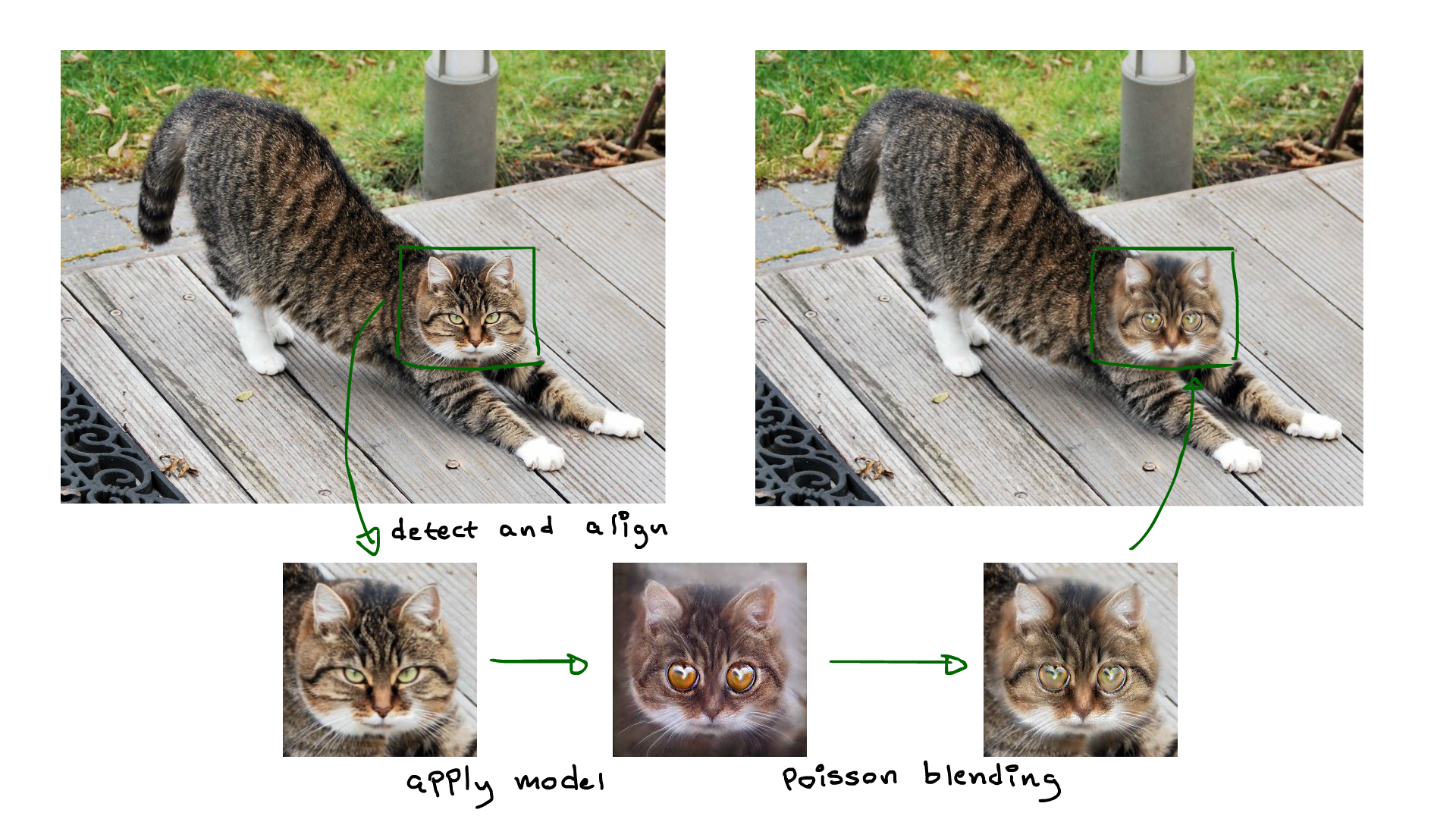
To test it out yourself try uploading an image of a cat in the demo at the top of the page, or check out the repo: https://github.com/DanielRapp/cat-filter for code to do stuff like this
